AI has been glorified as the future of automation, often portrayed as the ultimate solution for efficiency, decision-making, and innovation across industries. It has been marketed as an all-encompassing technology capable of transforming everything from healthcare and finance to autonomous systems and industrial processes.
In practice, this narrative does not match reality, as AI in its current form is too limited to be relied upon for mission-critical applications. While it has demonstrated some success in controlled settings, it struggles to adapt to real-world complexities and unpredictability. While tech giants celebrate cloud-trained AI models, these solutions typically fail spectacularly when deployed in dynamic, unpredictable environments. This is because AI lacks commonsense reasoning and struggles with real-world subtlety, i.e. it doesn’t understand the real world in the same way that humans do. It is typically trained on synthetic or limited datasets, which fail to fully capture the diverse and complex scenarios it is expected to handle. As a result, AI systems often misinterpret context, leading to unreliable or misleading outcomes in unpredictable operating environments.
The Consequences of AI’s Limitations
The lack of common sense of how the physical world works and limited training data is a fundamental limitation of AI systems. This can lead to costly failures, false predictions, and in worst cases, complete system breakdowns—making them unsuitable for environments where precision and reliability are paramount.
Another significant limitation, particularly for large-scale models like LLMs, is that AI models require powerful computing resources, making them inefficient for real-time, low-power edge applications. That being said, advancements in Nvidia’s latest chipsets, such as the Jetson Orin series are certainly helping bridge this gap by providing high-performance, power-efficient AI processing directly on edge devices.
While these new chipsets allow AI models to run locally and reduce reliance on cloud computing, AI in general still faces challenges such as excessive power consumption compared to deterministic DSP algorithm-based solutions, reliance on limited datasets, and a lack of explainability. These factors make AI unsuitable for industries requiring strict regulatory compliance and safety. While some smaller AI models can be optimised for edge deployment, many modern AI architectures remain computationally expensive and impractical for real-time, low-power edge applications.
Furthermore, most ML models rely on generalised feature extraction algorithms (mean, standard deviation, kurtosis, correlation etc) and are trained on limited, often unrealistic datasets. AI’s reasoning is entirely data-driven, meaning that we still don’t fully understand how the models work, making them very different from traditional DSP algorithms that use a mathematical recipe or a set of predefined rules. When faced with new, unseen conditions, AI often produces inaccurate or misleading results. In contrast, RTEI (Real-time Edge Intelligence) leverages DSP algorithms that are based on science, making them scientifically accurate and reliable in complex, real-world applications.
The AI Illusion: Why Traditional AI Fails at the Edge
Cloud-based AI solutions dominate today’s landscape because they require vast computational resources to function effectively. However, when deployed on edge devices with limited power and processing capacity, AI’s inefficiencies become apparent.
Predictive maintenance in industrial environments serves as a pertinent example. AI-based solutions are often promoted as game-changers, yet they struggle with a fundamental issue: the lack of real-world failure data. Most foremen and factory managers will not allow researchers to deliberately break machines for data collection, leading to AI models trained on synthetic or limited failure cases. As a consequence, this creates significant gaps in understanding of the normal and abnormal behaviour of the machine or process, leading to potential misdiagnoses and operational inefficiencies.
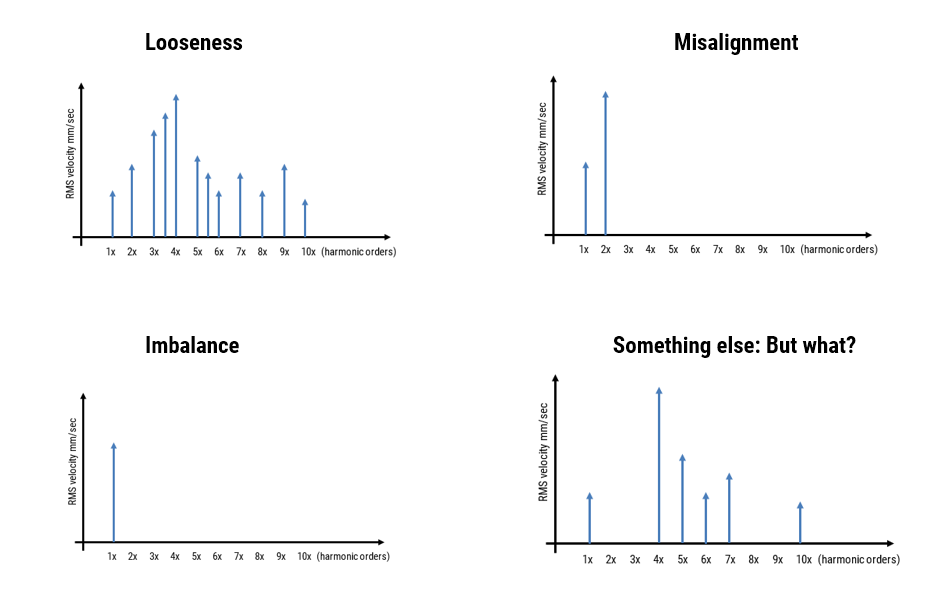
A more effective approach—Real-Time Edge Intelligence (RTEI)—combines DSP algorithms for feature extraction with ML models for classification. For example, in vibration analysis, DSP-based techniques can be used to generate harmonic fingerprints of velocity and displacement (feature extraction), which can be used to detect anomalies before they lead to system failure. These fingerprints or features are then fed into ML models for fault classification. This hybrid approach ensures accuracy and robustness, as DSP algorithms rely on physics and engineering principles (e.g. Fourier analysis, Kalman filtering) rather than data-driven learning.
RTEI: The Future of Edge Intelligence
RTEI (Real-time Edge Intelligence) represents a fundamental shift in AI for edge computing. By integrating real-time DSP algorithms with ML models, RTEI enhances accuracy, reliability, and computational efficiency. Unlike traditional AI, which operates on probabilistic reasoning, RTEI leverages fundamental scientific principles, making it more predictable and suited for mission-critical applications like autonomous vehicles, industrial automation, and medical diagnostics, where any misjudgements could have catastrophic consequences.
For Edge IoT to reach its true potential, intelligence must be embedded directly into devices. We are already seeing promising advancements—industrial-grade vibration analysis systems using real-time DSP algorithms to detect early signs of mechanical failure, and aircraft autopilot systems that rely on deterministic control algorithms rather than AI, ensuring mission-critical reliability in aviation, and self-driving cars that utilize LiDAR, cameras and other sensors to navigate autonomously without solely depending on AI-based decision-making. These systems prioritise reliability through scientifically proven methods rather than speculative, data-driven predictions.
As AI’s reasoning is fundamentally different to that of traditional DSP algorithms, a key point to realise here is that unlike DSP algorithms based on predefined rules and mathematical concepts (i.e. designed with human intelligence), how the AI reaches its result remains an enigma, and is the primary reason why they shouldn’t be allowed to operate without any scrutiny on critical processes.
RTEI enhances the overall solution by adapting its feature extraction algorithms to real-world variations, ensuring consistently high-quality data for AI classification. For example, when measuring analog sensor data using an ADC, temperature variations in the instrumentation electronics would cause the sampling rate to slightly vary. This variation would lead to a mismatch between the ideal model and real-world signal tendered to the classifier. As such, a conventional AI model would struggle, as these variations were probably not taken into account during the model’s training phase.
This is where DSP algorithms, such as a method that analyses timestamps or a Kalman filter can shine, as sampling rate variation can be taken into account in the estimation model. As such the DSP estimation algorithm can estimate the signal’s sampling rate in real-time and use this estimate to perform other operations required for the feature extraction operation. This ensures that only high-quality features are provided to the classifier in varying temperature environments—a very realistic scenario! Finally, it should be noted that this approach has the added advantage of requiring less ML training data, which expedites development and lowers project costs.
The Role of Arm Processors in RTEI
A major driving force behind this revolution is the Arm-based processor ecosystem. Unlike traditional cloud-based AI solutions, Arm Cortex processors (including the newer Arm Helium processors) provide a power-efficient way to run edge-optimized AI models in real-time. These processors are already at the core of smart sensors, embedded systems, and industrial automation, ensuring that AI-powered IoT devices can process and react instantly to changes in their environments.
Lockstep Processor Technology for Mission-Critical Systems
A fundamental aspect of mission-critical systems is Lockstep processor technology, which ensures redundancy and fault tolerance in real-time applications. Processors such as the Arm Cortex-R4 and Cortex-R5 are designed with lockstep functionality, where two identical processors run the same instructions simultaneously and compare results.
Lockstep technology is particularly useful for detecting hardware faults, which can arise from environmental influences, component ageing and external interference. For example, bit flips in memory can occur due to electromagnetic interference (EMI) from industrial machinery or power supply fluctuations, corrupting data memory and leading to algorithmic errors.
A key concept for dual-processor Lockstep processing is that it detects discrepancies but does not determine which processor is correct. Since both processors execute the same software, software bugs will appear identically on both, making lockstep ineffective for detecting programming errors. For true fault tolerance and error correction, a Triple Modular Redundancy (TMR) approach is often used, where three processors execute the same software, and a majority vote determines the correct outcome either per cycle or function.
ASIL Compliance and Automotive Safety
Lockstep technology is essential for Automotive Safety Integrity Level (ASIL) compliance, ensuring that automotive safety systems can detect and handle processor faults. For example, in an adaptive cruise control system, if a processor mismatch occurs, the system disengages cruise control rather than making an unsafe decision. This prioritisation of passenger safety over continuous operation is crucial for mission-critical applications.
For systems requiring the highest levels of reliability—such as flight control systems or nuclear power plants—TMR is employed to prevent a single fault from compromising the entire system.
Neoverse: High-Performance Edge Computing
Arm’s Neoverse architecture is a high-performance processor family designed for data centres, edge computing, and cloud infrastructure. Unlike Cortex processors, which are commonly used in mobile and embedded applications, Neoverse is optimized for scalability, power efficiency, and AI acceleration, making it well-suited for high-performance edge computing and is an interesting alternative to Nvidia’s Jetson Orin GPU series.
With advancements in Arm Cortex (especially Helium) and Neoverse architectures, developers can now deploy real-time AI workloads directly on edge devices, eliminating cloud dependencies. This means better security, reduced costs, and instant decision-making, all of which are essential for next-generation IoT applications.
Key takeway:The Evolution from AI to RTEI
Rather than dismissing AI’s role in edge applications, RTEI represents the next evolutionary step—one that acknowledges AI’s limitations and enhances its capabilities through deterministic DSP algorithms. Traditional AI struggles to generalize beyond pre-trained scenarios, lacks commonsense reasoning, and remains a black box in decision-making. These weaknesses make it ill-suited for dynamic, real-world applications.
The time has come to move beyond the assumption that cloud-trained AI can work everywhere. Instead, RTEI offers a hybrid intelligence system—combining the strengths of AI and DSP for real-time, reliable, and efficient edge intelligence.
By embedding intelligence directly into edge devices using Arm processors, lockstep technology, and deterministic DSP algorithms, we can build smarter, safer and more adaptable systems.
Sanjeev is a RTEI (Real-Time Edge Intelligence) visionary and expert in signals and systems with a track record of successfully developing over 25 commercial products. He is a Distinguished Arm Ambassador and advises top international blue chip companies on their AIoT/RTEI solutions and strategies for I4.0, telemedicine, smart healthcare, smart grids and smart buildings.
https://www.advsolned.com/wp-content/uploads/2024/10/robot_reading-scaled-e1729851827745.jpg7201080Dr. Sanjeev Sarpalhttps://www.advsolned.com/wp-content/uploads/2018/02/ASN_logo.jpgDr. Sanjeev Sarpal2025-01-31 15:05:132025-02-03 09:20:07Rethinking AI: Why Edge Intelligence must go beyond traditional ML
In modern computing, there are key concepts that define how machines process information and solve problems: Large Language Models (LLMs), algorithms, and computer programs. Each play a unique role in how tasks are performed and how intelligent systems operate.
LLMs, such as Chat-GPT, are advanced artificial intelligence models trained on massive amounts of text data to understand and generate human-like language responses. They excel at language-based tasks but rely on patterns from data rather having true intelligence based on human reasoning.
Algorithms, on the other hand, are step-by-step instructions (typically following a mathematical recipe), designed to solve specific problems or perform defined tasks. The rules or mathematical recipes that the algorithm follows have been designed by humans using reasoning and strict logic. As such, the output of the algorithm is deterministic, and can be recreate and explained by anybody following the method’s mathematical recipe or set of rules using the same input data.
Computer programs are the broader collection of code that encompasses both algorithms and models like LLMs, orchestrating various tasks by following sets of instructions. While algorithms are the building blocks for problem-solving, LLMs are specialized tools for tasks involving natural language, and programs bring these elements together to create functional software.
Understanding the differences between these three components helps clarify the architecture of modern computational systems. In this article, we discuss the differences between these terms and technologies, and provide hints and tips and a few practical examples for developers working on AIoT applications.
Programs and Algorithms: a Basic Example
A program consists of a set of instructions, often built upon one or more algorithms, to perform specific tasks based on a given input. An algorithm is a step-by-step procedure or formula for solving a problem, while a program is the implementation of that algorithm in a specific programming language.
For instance, consider a simple sorting algorithm like Bubble Sort, which can be implemented in a program:
The algorithm defines how to repeatedly compare and swap adjacent elements in a list until the list is sorted.
The program written in a language like Python or C++ implements this algorithm to sort any given list of numbers.
The key point is that a traditional program does not learn from the input or adapt its behaviour. It just follows the instructions of the algorithm every time based on the specific problem it is designed to solve.
LLMs: A Learning-Based Approach
In contrast, a Large Language Model (LLM) does not rely on predefined algorithms for specific tasks. Instead, it is trained on vast amounts of data and uses this training to predict responses based on learned patterns. For example:
If you ask an LLM to generate a recipe for pizza, it predicts the next word or sentence based on patterns it has seen in training data.
The LLM does not follow a fixed algorithm for generating recipes, but instead uses its learned understanding to predict the best response.
Unlike traditional programs, LLMs do not rely on strict rules or algorithms. They are probabilistic models that learn from a wide range of data, and their output is based on prediction rather than direct instruction.
Key Differences Between Programs and LLMs
Algorithm vs Learning: A traditional program follows strict instructions based on algorithms. LLMs, on the other hand, learn from data and use this learning to generate responses.
Fixed Output vs Prediction: In a program, the output is fixed for a given input based on the algorithm. An LLM predicts responses based on patterns, so the output can vary even with similar inputs.
No Adaptation vs Adaptation: Programs do not adapt or change their behavior unless reprogrammed. LLMs are capable of generating responses based on what they have learned, adapting to new inputs within the scope of their training.
Misconceptions about Algorithms and DLN/ML Models
Many people frequently refer to an ML model as an algorithm. This is incorrect, although the two terms are very closely related. In this section we discriminate between the two, and provide some practical examples.
Is it correct to distinguish between an ‘algorithm’ and a Deep Learning Network / ML model, as these terms are often used interchangeably but have distinct meanings?
An algorithm is a step-by-step procedure or set of rules for solving a problem, while a machine learning (ML) model is the output generated after an algorithm is applied to data during the training process. Essentially, an ML model is the learned representation or a mathematical construct based on an algorithm that can make predictions or decisions on new data.
For example, when training a neural network (which uses an algorithm like backpropagation), the result is an ML model that can classify images or recognize patterns. The algorithm guides the learning process, but the model is what performs the task after training.
What is an Algorithm?
As mentioned earlier, an algorithm is a set of rules or a mathematical recipe used to perform a specific task or to solve a problem. In ML, an algorithm is the method used to train an ML model. Examples include linear regression, decision trees, k-nearest neighbors and gradient descent.
Algorithms are very well established in the IoT sensor world for a variety of tasks, such as instrumentation and measurement, cleaning sensor data, AR (augmented reality), predictive maintenance with MEMS sensors and navigation (drones, cars and robotics). The latter makes heavy use of Kalman filtering and sensor fusion, which has been used with great success for decades.
As a simple example of an algorithm, consider the task of calculating the mean or average of set of numbers in the following dataset, \(z=[3,2,1,4,6]\). The mean can be calculated using the following mathematical recipe,
Note that this result is deterministic, in the sense that it can be recreated and more importantly explained by anybody following the function’s mathematical recipe using the same input data. This is very different to a ML model that would also reach the same result for the same input dataset, but as discussed in the next section, explaining how the model reached the result remains an enigma.
What is a DLN/ML Model?
An ML model is the resulting output or predicted result after training an algorithm on a various datasets. It typically uses various feature extraction algorithms (e.g. mean, standard deviation and correlation) during the training period in order to extract features of interest for the ML model. The resulting model represents the learned patterns, parameters, or rules that can be used to make predictions on new data.
A key point to realise here, is that unlike algorithms based on predefined rules and mathematical concepts, how the ML model reaches its result remains an enigma, and is the primary reason why they shouldn’t be allowed to operate without any scrutiny on critical processes. As such, AI systems are energy constrained Boltzmann machine models, as the model is trained on data.
In many AIoT applications, Kalman based sensor fusion is typically used for feeding the ML model with high quality features of the underlying process, thus significantly improving the accuracy of the AI system.
How Algorithms and DLN/ML Models Interact
A model provides the capability to make decisions based on input data. It can recognize patterns, make predictions, and adapt to new information. Essentially, a model simulates cognitive functions that are typically associated with human thinking, such as dealing with ambiguity and uncertainty, but as discussed in a previous article, AI does not have any common sense, as it has no understanding of the underlying data or process that it is modelling.
On the other hand, an algorithm is a set of defined instructions or a mathematical recipe. It is a rules based step-by-step procedure used for calculations, data processing, and automated reasoning tasks. Algorithms are the backbone of software and can solve a wide range of problems by following their defined logic.
However, not all functions are computable. This means that there are certain problems for which no algorithm can be formulated to provide a solution. These are referred to as non-computable functions. In such cases, even the most advanced algorithms cannot determine an outcome, highlighting a fundamental limitation in computational theory.
Human Intelligence and Digital Intelligence
In the field of computation, it is essential to differentiate between traditional algorithms and machine learning models. An algorithm is a direct output of human intelligence, crafted through logical reasoning and problem-solving techniques. It represents a set of predefined instructions designed to solve specific problems. The human mind formulates these steps to ensure a consistent and accurate outcome.
In contrast, a trained machine learning (ML) model is the product of digital intelligence. While algorithms underpin the model’s structure, the true power of an ML model arises through its capacity to learn and adapt from new training data. This process involves iteratively adjusting parameters to optimize performance in tasks like prediction, classification, or decision-making. In this sense, the model evolves beyond its initial algorithmic foundation, generating insights and results that may not be directly encoded by human logic.
“An algorithm is a direct manifestation of human intelligence, designed through logic, reasoning, and problem-solving techniques. On the other hand, a trained machine learning model represents the outcome of digital intelligence, which evolves through the iterative processing of data.”
The convergence of these two forms of intelligence—human and digital—marks a significant shift in computational systems. Algorithms, though foundational, are static and require manual updates. Machine learning models, by contrast, learn from experience, dynamically evolving with each new piece of training data. This shift positions ML models as more flexible and adaptive tools for solving complex problems where human-defined rules may fall short.
The distinction between human-driven algorithms and data-driven machine learning models emphasizes the growing role of adaptive systems in areas such as autonomous driving, personalized medicine, and financial forecasting. As machine learning continues to evolve, the boundaries between explicit programming and emergent behavior will continue to blur, paving the way for systems capable of independent learning and decision-making.
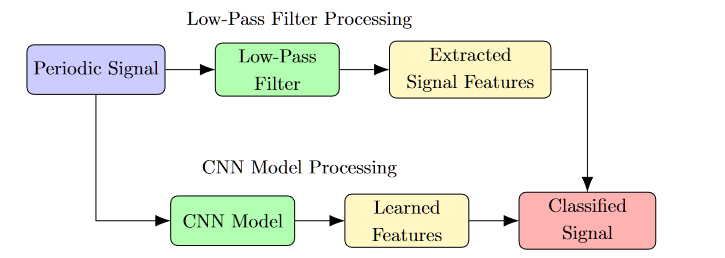
Low-Pass Filter and CNN for Classifying Periodic Signals
Both a Low-Pass Filter (LPF) and a Convolutional Neural Network (CNN) can be employed to handle periodic signals, but their approaches and purposes differ fundamentally.
Low-Pass Filter (LPF)
A Low-Pass Filter is an algorithm designed to attenuate the high-frequency components of a signal while allowing the low-frequency components to pass. Its primary use is to filter or clean a signal rather than classify it. Applications of the LPF in AIoT, include removing glitches from sensor data or even cleaning up noise on a measured periodic signal prior to feature extraction and subsequent ML classification, leading to higher accuracy.
A practical IIR (infinite impulse response) digital filter used in both AIoT and IoT may be defined in terms of a finite number of poles \(p\) and zeros \(q\), as defined by the linear constant coefficient difference equation,
where, \(a_k\) and \(b_k\) are the filter’s denominator and numerator polynomial coefficients, who’s roots are equal to the filter’s poles and zeros respectively. LPF filter can used for all types of signals, not just periodic signals. However, for this article we limit the discussion to periodic signals.
Limitations for Classification
While an LPF can enhance a periodic signal by reducing high-frequency noise, it does not classify the signal. It merely transforms the input based on fixed mathematical operations, with no ability to learn from data or adapt its behaviour.
Convolutional Neural Network (CNN)
A Convolutional Neural Network (CNN) is a machine learning model designed to recognize patterns in data by learning from training examples. It can be trained to classify periodic signals by learning distinctive features in the signal’s structure.
Operation
The CNN applies a series of convolution operations:
where \(I\) is the input signal, \(K\)is the kernel, and \(S(i,j)\) is the resulting feature map.
Classification
Unlike the LPF, the CNN is capable of learning to classify different periodic signals through training. The learned filters allow the network to distinguish between signals based on the periodic features it identifies.
Extraction vs Learned feature
Low-Pass Filter: Performs a deterministic operation that modifies the signal but cannot classify it.
CNN: Learns from data and can classify periodic signals by recognizing their features.
In conclusion, while a Low-Pass Filter may assist in signal preprocessing, a CNN is required for the task of classifying signals.
Adaptive Low-Pass Filters
An adaptive low-pass filter (LPF), such as those based on the Least Mean Squares (LMS) algorithm, introduces several key features and benefits compared to a traditional, static LPF:
Dynamic Adaptability: Adaptive LPFs adjust their characteristics in response to variations in the input signal, allowing for real-time filtering of noise or unwanted frequencies, especially in non-stationary signals.
Error Minimization: These filters utilize a feedback mechanism to minimize the difference (error) between the desired output and the actual output. The filter coefficients are continuously updated based on this error, enhancing the filter’s adaptability to changing signal conditions.
Improved Performance in Noisy Environments: Adaptive LPFs effectively reduce noise by optimizing signal quality, which is particularly valuable in applications like audio processing, telecommunications, and biomedical signal processing where signal characteristics can fluctuate.
Applications in Real-Time Systems: The adaptability of these filters makes them suitable for real-time systems, such as echo cancellation in telecommunication, where the noise characteristics may vary dynamically, ensuring consistent performance over time.
Computational Complexity: While adaptive filters provide significant advantages, they also come with increased computational complexity due to the need for constant updates to the filter coefficients, which can be a concern in systems with limited processing capabilities.
In summary, using an adaptive LPF enhances the filter’s ability to handle varying signal conditions effectively, making it particularly valuable in applications requiring real-time signal processing, thus improving overall performance and robustness against noise and interference.
Adaptive low-pass filter (LPF) differs significantly from a traditional LPF in terms of feature extraction and learning capabilities.
Feature Extraction vs. Feature Learning
Traditional LPF: This filter focuses on extracting specific frequency components from a signal by applying fixed coefficients determined by the filter design, which remain constant during operation. As a result, it extracts features based on pre-defined criteria.
Adaptive LPF: Utilizes algorithms like the Least Mean Squares (LMS) to adjust its filter coefficients in real-time based on the input signal characteristics. This enables the adaptive LPF to extract features that dynamically correspond to changing signal conditions, but it does not learn features in the same manner as a neural network.
Comparison with CNNs
Convolutional Neural Networks (CNNs): CNNs are designed to learn features from data through multiple layers, allowing them to automatically extract high-level features from raw inputs. Unlike traditional LPFs, CNNs perform feature learning, adapting to the input data through training on labeled datasets.
While adaptive LPFs adjust their response based on signal changes, they do not perform feature learning like CNNs. They can optimize their filter characteristics based on feedback but lack the hierarchical feature learning approach present in CNNs.
Adaptive LPFs can extract features based on the immediate conditions of the signal; however, they do not ‘learn’ features in the same way that CNNs do. Instead, adaptive LPFs optimize the extraction process in real-time, making them effective in environments where signal characteristics vary.
Comparison of Adaptive Low-Pass Filters and Convolutional Neural Networks
Adaptive low-pass filters (LPFs), such as those using the Least Mean Squares (LMS) algorithm, exhibit several similarities with convolutional neural networks (CNNs) regarding their operational principles and learning mechanisms.
Adaptive Coefficients: Adaptive LPFs modify their coefficients based on the input signal, similar to how CNNs adjust their weights during training to minimize loss on a dataset.
Supervised Learning: Both systems can be trained using labeled data to optimize performance. Adaptive filters adjust based on real-time feedback while CNNs learn complex patterns through multiple iterations.
Feature Extraction: Adaptive LPFs extract relevant features dynamically, while CNNs automatically learn to identify hierarchical features through their architecture.
Learning Methodology: Adaptive LPFs adjust their parameters based on incoming data but do not learn complex representations as CNNs do. CNNs can learn multiple levels of abstraction through backpropagation.
Structure and Complexity: CNNs consist of multiple layers, allowing them to learn intricate patterns, whereas adaptive LPFs typically operate with a single, simpler structure focused on modifying coefficients.
Items 1,2 and 3 are similar, but item 4 and 5 are different.
While adaptive LPFs and CNNs share similarities in their adaptive behaviors and feature extraction capabilities, they fundamentally differ in methodologies and complexities. Adaptive LPFs do not fully replicate the intricate learning capabilities of CNNs, though both aim to improve task performance through adaptation.
Comparison of Adaptive LPFs and CNNs
Order of the Filter: The order of an adaptive low-pass filter (LPF) determines its ability to capture and process complex signal characteristics. A higher-order filter can approximate a more complex frequency response, allowing it to better handle diverse signal patterns, similar to how a deeper convolutional neural network (CNN) can learn more complex representations.
Learning Capabilities: While both CNNs and adaptive LPFs adjust their parameters based on input, CNNs inherently possess a more advanced learning capability through multiple layers, each designed to extract different levels of abstraction from the data. This allows CNNs to learn hierarchical feature representations effectively. In contrast, increasing the order of an adaptive LPF can enhance its feature extraction capabilities, but it still lacks the sophisticated learning mechanisms that CNNs implement, such as backpropagation and convolutional operations.
Complex Features: CNNs excel in extracting spatial hierarchies in data (e.g., images) by applying filters across multiple layers, progressively identifying edges, shapes, and more abstract features. Adaptive LPFs, when designed with a higher order, can capture complex signal behaviours, but their ability to generalize or learn from large datasets is limited compared to CNNs.
While increasing the order of an adaptive LPF can enhance its performance in signal processing, it does not equate to the deep learning capabilities of CNNs. CNNs utilize their layered architecture to learn complex features in a more robust and generalized manner, making them more suitable for tasks like image recognition and classification.
Parameter Estimation
Parameter estimation plays a crucial role in both traditional algorithmic processes and machine learning. It involves determining the best parameters for a given model based on observed data.
Algorithmic Parameter Estimation
In traditional algorithmic contexts, parameter estimation involves using specific algorithms to find optimal parameters for mathematical models. Key methods include:
Least Squares Estimation (LSE)
This method minimizes the sum of the squared differences between observed and predicted values. The parameter estimation is given by:
where \(\hat{\theta}\) denotes the estimated parameters. this concept is is central to Kalman filtering, whereby a state-space model of the process to be modelled uses the state estimates (i.e. the parameters of interest) to perform the prediction. The Kalman update equations attempt to minimise the error between the model output and the observed data in a least squares sense on a sample-by-sample basis.
Maximum Likelihood Estimation (MLE)
MLE estimates parameters by maximizing the likelihood function, which reflects the probability of the observed data under the model parameters:
where \(p(\theta | \text{data})\) is the posterior distribution.
In both traditional algorithms and machine learning contexts, the aim is to find the optimal parameters that best fit the model to the observed data.
Key Takeaways
Many people frequently refer to an ML model as an algorithm. This is incorrect, although the two terms are very closely related. An algorithm is a direct output of human intelligence, crafted through logical reasoning and problem-solving techniques. It represents a set of predefined instructions or a mathematical recipe designed to solve specific problems. The human mind formulates these steps to ensure a consistent and accurate outcome. In contrast, a trained machine learning (ML) model is the product of digital intelligence that uses algorithms and datasets to construct an ML model.
A key takeaway is that algorithms are based on predefined rules and mathematical concepts, whereas AI systems are energy constrained Boltzmann machine models, as the model is trained on data. As such, how an ML model reaches its result remains an enigma, and is the primary reason why they shouldn’t be allowed to operate without any scrutiny on critical processes.
Sanjeev is a RTEI (Real-Time Edge Intelligence) visionary and expert in signals and systems with a track record of successfully developing over 25 commercial products. He is a Distinguished Arm Ambassador and advises top international blue chip companies on their AIoT/RTEI solutions and strategies for I4.0, telemedicine, smart healthcare, smart grids and smart buildings.
Jayakumar is an Arm ambassador and seasoned expert in semiconductor technology and AIoT. He advices companies such as Mistral Solutions, SunPlus Software, and Apollo Tyres at the strategic level on their AIoT solutions. He successfully founded Epigon Media Technologies, which focuses on Research and Development for the global market, and is also the co-author of the book "Deep Learning Networks: Design, Development, and Deployment."
https://www.advsolned.com/wp-content/uploads/2024/10/robot_reading-scaled-e1729851827745.jpg7201080Dr. Sanjeev Sarpalhttps://www.advsolned.com/wp-content/uploads/2018/02/ASN_logo.jpgDr. Sanjeev Sarpal2024-10-25 12:27:242024-10-25 14:30:58An AI/ML model is not an algorithm
Over the last few years, there has been tremendous interest in the possibility of replacing humans at the workplace with AI. One obvious advantage is AI’s ability to process massive amounts of data and perform tasks such as repetitive tasks (such as data entry) much more efficiently than humans, leading to higher productivity and reduced operational costs. AI can also work continuously without fatigue, ensuring 24/7 customer service. However, can AI truly think and rationalise like a human?
Challenges in understanding of the real-world
Our experience with AI systems suggests categorically that AI’s current limitation is that it does not have any common sense, as there is no reasoning component in the current generation AI model-based inference. As such, current AI does not truly understand the world the way humans do. AI models are trained on large datasets, which are essentially collections of text, images, sensor data etc, and generates responses based on statistical correlations in data. While they can learn patterns and extract important features from this data, they don’t inherently understand the meaning of this data. Understanding is a fundamental component of human intelligence and commonsense, allowing us to take actions and draw conclusions that may seem logical to some, but irrational to people with other experiences in life. In short, we can conclude that commonsense is built up from real-world experiences, social interactions, emotions and context, which is something that AI currently lacks.
The aforementioned acknowledges that current AI models lack commonsense due to the absence of reasoning components. Also, there is the potential for AI models to converge on solutions that may not adhere to Bayesian learning principles, which is an important consideration. We’ll now look at this aspect in depth with a few examples, but we’ll start off with examples of where having no common sense can be turned to an advantage.
Transparency and fake news
Having no common sense and no real understanding of the data can also be turned into an advantage. Consider the example of an AI sorting through CVs (resumes) of suitable candidates for a job. The model can be limited to just focus on the work experience and education, and ignore the name, gender and nationality, making the process much more transparent. Humans will generally try and form a picture in their heads about the candidate and may then appraise the CV with prejudice rather than merit.
Perhaps one of the best examples of AI has been in the media. Whereby a model can be fed with a certain narrative (e.g. anti-abortion or pro-war) and then instructed to produce a new article, filling in the details with arbitrary photos and facts taken from other media sources, and older publications. Many of the articles are not verified by an editorial team before publication, resulting in unconfirmed stories making it to the news websites. This is not just limited to news, reviewers of several scientific publications have also reported fake articles sent for review – some of which have been published, which is an area of concern for the scientific community.
Is it a Dog or a Cat?
Consider an AI model trained to classify images of animals. The model can accurately classify images of cats and dogs when presented with typical images of these animals. However, when presented with an unusual image, the model might fail to classify it correctly due to the lack of reasoning and common sense.
For instance, if the AI model is given an image of a cat wearing a dog costume, it might classify the image as a dog because it lacks the reasoning component to understand that the core features of a cat are still present despite the costume. A human, using common sense, would easily identify the animal as a cat in a dog’s costume.
In this example, the AI model converges on a solution that classifies the image as a dog, which may disobey Bayesian learning principles that consider the prior probability of encountering a cat versus a dog in such a context.
This limitation highlights the importance of integrating reasoning components into AI models to enhance their common sense and improve their ability to handle unusual or unexpected situations effectively.
Bayesian learning enhances deep learning networks by providing uncertainty quantification, preventing overfitting, facilitating model comparison, enabling data-efficient learning, and improving interpretability. This makes Bayesian approaches highly valuable in critical applications where reliability, robustness, and transparency are paramount. More information can be found in the following video.
Data vs Science for IoT T&M applications
Many IoT test and measurement (T&M) and calibration methods use sinewaves to check compliance of the DUT (device under test) by measuring the sinewave’s amplitude, some examples include:
Measuring material fatigue/strain with a loadcell – in vehicle and bridge/building applications measuring material fatigue and strain is essential for safety. An AC sinusoidal excitation overcomes the difficulty of dealing with instrumentation electronics DC offsets.
Calibrating CT (current transformers) sensors channels – a sinusoid of known amplitude is applied to channel input and the output amplitude is measured.
Measuring gas concentration in infra-red gas sensors – the resulting sinusoid’s amplitude is used to provide an estimate of gas concentration.
Measuring harmonic amplitudes in power quality smart grids applications – in 50/60Hz power systems, certain harmonic amplitudes are of interest.
ECG biomedical compliance testing (IEC60601-2-47) – channel compliance with IEC regulations needed for FDA testing typically uses a set of sinewaves at known amplitudes, to ensure that the channel’s signal chain amplitude error is within specification.
The latter example is particularly interesting, as the basic idea is to measure the amplitude differences in the DUT’s signal chain for a set of sinewaves at 0.67, 1, 2, 10, 20 and 40Hz with respect to a 5Hz reference sinewave. Where, it is assumed the amplitude of all input sinewaves remains constant, and that the relative amplitude error must be within ±3dB for the signal chain to be classed as IEC compliant.
There are a number of signal processing methods that can be employed to perform the estimation, such as the FFT, AM modulation, Hilbert transform and full-wave rectification. All of these methods require extra filtering operations and the FFT for examples, requires low frequency trend removal (usually a DC offset), and windowing so there a number of factors to take into consideration, which complicates the challenge. The FFT is perhaps one of the most widely used methods but is limited by its frequency resolution, which leads to a bias on the amplitude estimate if it’s not centred at a multiple of the ideal frequency bin resolution (\(F_s/N\)).
As most IoT devices use a low-cost oscillator, the sampling rate error can be as high as ±3%, leading to a significant bias in the amplitude estimation using the FFT method. Therefore, an important first step for establishing an estimate of the sinewave’s amplitude is to estimate the exact sampling frequency of the DUT.
Another simpler method that we’ve seen on some IoT devices, is to use high time-resolution timestamps from a higher accuracy crystal oscillator, but for lower-cost IoT devices this may not be available, so it’s better to have a strategy that extracts the exact sampling rate from the dataset.
Sampling rate estimation using AI
Sampling rate estimation can be achieved using AI, whereby datasets of the known input test sinewaves are collected for subsets of the ideal sampling rate. For many IoT ECG devices, 200Hz is typically used. Therefore, assuming an ideal sampling rate of 200Hz, we can generate test sinewave data sampled at 199.5Hz, 199.6Hz…..200.4Hz, 200.5Hz etc. This collection of sinewave data can then be fed into an ML classifier for estimation of the true sampling rate. Assuming that the training dataset is large enough to cover all required scenarios, this method will work.
However, it should be noted that this approach doesn’t have any commonsense, since it’s purely based on data and has no understanding of the physical process that it’s modelling. This becomes apparent if the sampling error is, say 199.54Hz. As the model doesn’t have any data for this scenario and doesn’t have any commonsense and as such can’t improvise, it must choose between 199.5Hz and 199.6Hz which will lead to a bias in the true sampling rate estimate. Another problem appears if another sampling rate or other test frequencies are used, as these were not taken into account during the training process.
Sampling rate estimation using a UKF
An alternative approach is to model the physical process using an Unscented Kalman Filter (UKF). The UKF’s flexibility allows for a more detailed mathematical model of the process to be implemented, leading to the possibility of estimating the sinewave’s amplitude, phase, DC offset as well as the true sampling rate.
Assuming stationarity, a mathematical model of the process can be described as,
Where, \(\theta\) is initial phase offset, \(v(n)\) is the measurement noise and \(A\) (sinewave’s amplitude), \(B\) (signal’s DC offset) and \(F_s\) (sampling rate) are the parameters that we want to estimate.
This model can be broken down and the entities of interest (\(A, B\) and \(F_s\)) implemented as state variables in the Kalman update equations. Notice that although the phase of sinewave is linear, the output of the \(\sin()\) function is non-linear, which means that the relationship between the observed signal to the entity of interest (\(F_s\) in our case) is non-linear. This is the main reason for choosing the UKF, as it is well suited to handling non-linear relationships. A description of the UKF equations is beyond the scope of this article, but the reader is referred to some of the excellent textbooks on the UKF for a complete description of the algorithm.
Assuming that the test sinewave is high accuracy – a realistic assumption since a modern calibrated signal generator has frequency error in the \(\mu\)Hz region, we can use the Kalman filtering equations to estimate the true sampling rate over time. An important to point to realise is that like the AI method described above, the UKF also doesn’t have any commonsense, but has the virtue of ‘understanding’ the process that it’s modelling by virtue of the mathematical model implemented in its update equations. This means that a sinewave of any frequency and sampling rate can be applied to the UKF, and assuming that the exact sinewave frequency is also entered into the state equations, the UKF method will always work.
However, one potential weakness of the method for this application is that the Kalman filter is a statistical state estimation method, meaning that its state estimation will be optimal in a statistical sense, but not necessarily in a deterministic sense. This means that there is no guarantee that the state estimates will be correct in a deterministic (absolute) sense.
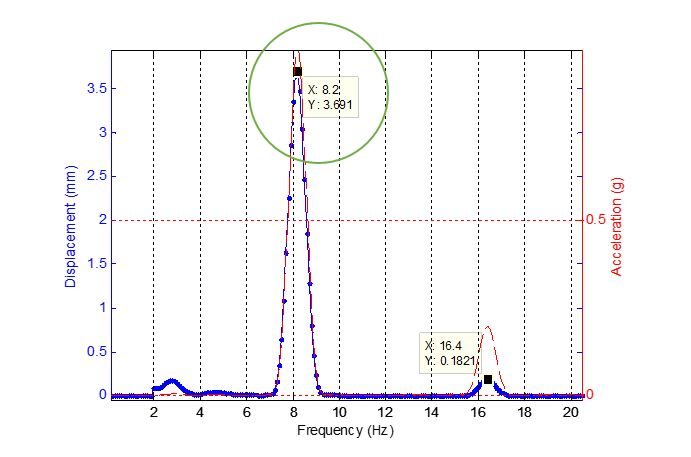
An animation of the UKF estimation for a 32.3Hz sinewave, sampled at 100Hz with a 0.1% sampling rate error (100.1Hz) is shown below, as seen the UKF correctly estimates the state-estimates of the test sinewave within 1 second.
AI in weapons technology
Recently, much emphasis has been placed on developing smart weapons using AI technology. Major weapons manufacturers from all over the world are currently experimenting with AI-based drone technology that can be used to attack enemy combatants in swarms as well deploying GPS-guided smart munitions and developing new EW (electronic warfare) jamming technology.
Many Western nations allocate substantial resources to defence spending, with significant portions of their budgets dedicated to military operations and technological advancements. However, modern conflict zones highlight the evolving challenges that defence systems face, particularly in terms of operational complexity and sustainability in international theatres of operation.
Looking further to the East, nations such as Russia and China allocate a much smaller budget to their military-industrial complex. Their approach focuses instead on utilizing AI in a more targeted manner, emphasizing established scientific and mathematical principles, such as control theory, with AI applied for classification purposes. Over recent years, as repeatly demostrated in various international conflict zones, this strategy has proven to be very effective. Technologies like hypersonic missiles and electronic warfare systems developed by Russia have managed to evade many Western air defense systems, altering the balance of power in several theatres of operation. This impressive performance challenges the notion that simply investing large sums of money into AI weapons technology guarantees superior results.
Returning to the subject at hand, all of these AI smart weapons still lack any common sense as the AI cannot reason like a human. As such, it is dangerous to allow these systems to operate autonomously and to have high expectations of their performance in a combat situation. That being said, researchers working at Russia’s AIRI research institute contend to have taken significant steps forward in developing the world’s first self-learning AI system (Headless-AD) that can adapt to new situations/tasks without any human intervention by autoregressively predicting actions using the AI’s existing learning history model as context. If successful, Headless-AD would be a great leap forward in developing sentient AI technology for all walks of life.
Human Intelligence and Digital Intelligence
In the field of computation, it is essential to differentiate between traditional algorithms and machine learning models. An algorithm is a direct output of human intelligence, crafted through logical reasoning and problem-solving techniques. It represents a set of predefined instructions designed to solve specific problems. The human mind formulates these steps to ensure a consistent and accurate outcome.
In contrast, a trained machine learning (ML) model is the product of digital intelligence. While algorithms underpin the model’s structure, the true power of an ML model arises through its capacity to learn from large scale data. This process involves adjusting parameters during the training period (not during the inference time/runtime) to optimize performance in tasks like prediction, classification, or decision-making. In this sense, the model evolves beyond its initial algorithmic foundation, generating insights and results that may not be directly encoded by human logic.
An algorithm is a direct manifestation of human intelligence, designed through logic, reasoning, and problem-solving techniques. On the other hand, a trained machine learning model represents the outcome of digital intelligence, which evolves through the iterative processing of data.
The convergence of these two forms of intelligence—human and digital—marks a significant shift in computational systems. Algorithms, though foundational, are static and require manual updates. Machine learning models, by contrast, can be improved by providing them with more training data when available. This shift positions ML models as more flexible and adaptive tools for solving complex problems where human-defined rules may fall short.
The distinction between human-driven algorithms and data-driven machine learning models emphasizes the growing role of adaptive systems in areas such as autonomous driving, personalized medicine, and financial forecasting. As machine learning continues to evolve, the boundaries between explicit programming and emergent behavior will continue to blur, paving the way for systems capable of independent learning and decision-making.
Key takeaways
There has been considerable interest in the potential of replacing human roles in the workplace with AI. However, as discussed herein, AI fundamentally lacks an understanding of the meaning behind the data it processes for classification tasks. This ‘lack of understanding’ is a core component of human intelligence and common sense, which enables individuals to make decisions and draw conclusions that may appear logical to some but irrational to others based on varying life experiences. In essence, common sense is derived from real-world experiences, social interactions, emotions, and context—attributes that AI currently lacks and is unlikely to acquire in the foreseeable future.
Nevertheless, the absence of common sense and a deep understanding of data can also be leveraged to create a more transparent process for job applicants and application reviews. Conversely, AI can be utilized to generate misleading information shaped by influential entities to support specific narratives and sway public opinion.
Sanjeev is a RTEI (Real-Time Edge Intelligence) visionary and expert in signals and systems with a track record of successfully developing over 25 commercial products. He is a Distinguished Arm Ambassador and advises top international blue chip companies on their AIoT/RTEI solutions and strategies for I4.0, telemedicine, smart healthcare, smart grids and smart buildings.
Jayakumar is an Arm ambassador and seasoned expert in semiconductor technology and AIoT. He advices companies such as Mistral Solutions, SunPlus Software, and Apollo Tyres at the strategic level on their AIoT solutions. He successfully founded Epigon Media Technologies, which focuses on Research and Development for the global market, and is also the co-author of the book "Deep Learning Networks: Design, Development, and Deployment."
https://www.advsolned.com/wp-content/uploads/2024/09/Robot_thinking.jpg19911991Dr. Sanjeev Sarpalhttps://www.advsolned.com/wp-content/uploads/2018/02/ASN_logo.jpgDr. Sanjeev Sarpal2024-09-17 15:54:062024-09-17 16:16:26From IoT to AIoT: is it true that AI doesn’t have any common sense?
AI (Artificial Intelligence) has its roots with the famous mathematician Alan Turing, who was the first known person to conduct substantial research into the field that he referred to as machine intelligence. Turing’s work was published as Artificial Intelligence and was formally categorised as an academic discipline in 1956. In the years following, work undertaken at IBM by Arthur Samuel led to the term Machine Learning, and the field was born.
In terms of definitions: AI is an umbrella term, whereas ML (Machine Learning) is a more specific subset of AI focused on producing inference using trained networks. During training, the dataset plays a key role in ML quality during inference. AI provides scope for ML and Deep Learning. In fact, Deep Learning Networks use amazing Transformer models for the current generation AI world.
AI is the overarching field focused on creating intelligent systems, whereas ML is a subset of AI that involves creating models to learn from data and make decisions.
ML is crucial for IoT because it enables efficient data analysis, predictive maintenance, smart automation, anomaly detection, and personalized user experiences, all of which are essential for maximizing the value and effectiveness of IoT deployments.
The difference between AI and ML in a nutshell
Artificial Intelligence (AI):
Definition: AI is a broad field of computer science focused on creating systems capable of performing tasks that normally require human intelligence. These tasks include reasoning, learning, problem-solving, perception, and language understanding.
Scope: Encompasses a wide range of technologies and methodologies, including machine learning, robotics, natural language processing, and more.
Example Applications: Voice assistants (e.g., Siri, Alexa), autonomous vehicles, game-playing agents (e.g., AlphaGo), and expert systems.
Machine Learning (ML):
Definition: ML is a subset of AI that involves the development of algorithms and statistical models that enable computers to learn from and make predictions or decisions based on data.
Scope: Focused specifically on creating models that can identify patterns in data and improve their performance over time without being explicitly programmed for specific tasks.
Example Applications: Spam detection, image recognition, recommendation systems (e.g., Netflix, Amazon), predictive maintenance of critical machinery and identifying medical conditions, such as heart arrhythmias and tracking vital life signs – the so called IoMT (Internet of Medical Things).
Why We Need ML for IoT
Data Analysis:
Massive Data: IoT devices generate a vast amount of data. ML is essential for analyzing this data to extract meaningful insights, detect patterns, and make informed decisions.
Real-Time Processing: ML models can process and analyze data in real-time, enabling immediate responses to changes in the environment, which is crucial for applications like autonomous vehicles and smart grids. They are also an invaluable tool for monitoring human well-being, such as tracking vital life signs, and checking motion sensor data for falls and epileptic fits in elderly and vulnerable persons.
Automation:
Smart Automation: ML enables IoT devices to automate complex tasks that require decision-making capabilities, such as adjusting climate control systems in smart buildings based on occupancy patterns.
Adaptability: ML models can adapt to changing conditions and improve their performance over time, leading to more efficient and effective automation.
Personalization:
User Experience: ML can analyze user preferences and behaviors to personalize experiences, such as recommending products, adjusting device settings, or providing personalized health insights from wearable devices.
Enhanced Interaction: Improves the interaction between users and IoT devices by making them more intuitive and responsive to individual needs.
What is AIoT exactly?
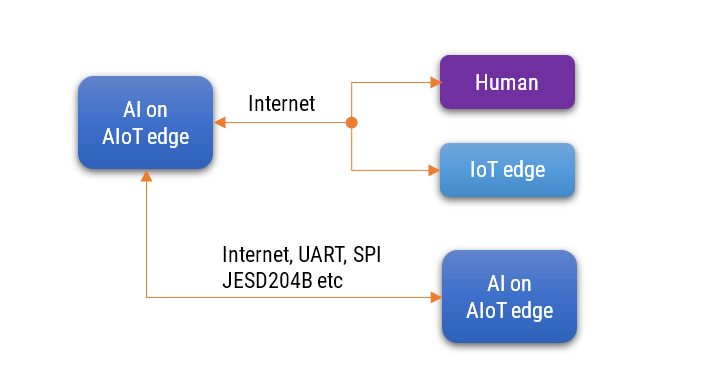
IoT nodes or edge devices use convolutional neural networks (CNN) or neural networks (NN) to perform inference on data collected locally. These devices can include cameras, microphones, or UAV-based sensors. By having the ability to perform inference locally on IoT devices, it enables intelligent communication or interaction with these devices. Other devices involved in the interaction can also be IoT devices, human users, or AIoT devices. This creates opportunities for AIoT (Artificial Intelligence of Things) rather than just IoT, as it facilitates more advanced and intelligent interactions between devices and humans.
AIoT is interaction with another AIoT. In this case, there is a need for artificial intelligence on both sides to have a meaningful interaction.
AIoT is interaction with IoT. In this case, there is a need for artificial intelligence on one side, and no AI on the other side. Thus, it is not a good and safe configuration for deployment.
AIoT is interaction with a human. In this case, there is a need for artificial intelligence on one side and a human on the other side. This is a good configuration because the volume of data from the device to the human will be less.
Human Also in the Loop is a Thing of the Past
Historically, humans have used sensor devices, now referred to as IoT edges or nodes, to perform measurements before making decisions based on a particular set of data. In this process, both humans and IoT edge devices participate. Interaction between one IoT edge and another is common, but typically within restricted applications or well-defined subsystems. With the rise of AI technologies, such as ChatGPT and Watsonx, AI-enabled IoT devices are increasingly interacting with other IoT devices that also incorporate AI. This interaction is prevalent in advanced driver-assistance systems (ADAS) with Level 5 autonomy in vehicles. In earlier terms, this concept was known as Self-Organizing Networks or Cognitive Systems.
The interaction between two AIoT systems introduces new challenges in sensor fusion. For instance, the classic Byzantine Generals Problem has evolved into the Brooks-Iyengar Algorithms, which use interval measurements instead of point measurements to address Byzantine issues. This sensor fusion problem is closely related to the collaborative filtering problem. In this context, sensors must reach a consensus on given data from a group of sensors rather than relying on a single sensor. Traditionally, M measurements with N samples per measurement produce one outcome by averaging data over intervals and across sensor measurements.
Sensor fusion involves integrating data from multiple sensors to obtain more accurate and reliable information than what is possible with individual sensors. By rethinking this problem through the lens of collaborative filtering—an approach widely used in recommendation systems—we can uncover innovative solutions. In this analogy, sensors are akin to users, measurements are comparable to ratings, and the environmental parameters being measured are analogous to items. The goal is to achieve a consensus measurement, similar to how collaborative filtering aims to predict user preferences by aggregating various inputs. Applying collaborative filtering techniques to sensor fusion offers several advantages. Matrix factorization can reveal underlying patterns in the sensor data, handling noise and missing data effectively. Neighborhood-based methods leverage the similarity between sensors to weigh their contributions, enhancing measurement accuracy.
Probabilistic models, such as Bayesian approaches, provide a robust framework for managing uncertainty. By adopting these methods, we can improve the robustness, scalability, and flexibility of sensor fusion, paving the way for more precise and dependable applications in autonomous vehicles, smart cities, and environmental monitoring.
Kalman filtering and collaborative filtering represent two distinct approaches to processing sensor data, each with unique strengths and applications.
Kalman filtering is a recursive algorithm used for estimating the state of a dynamic system from noisy observed measurement data. It excels in real-time applications, offering a mathematically rigorous method of statistically estimating and predicting a model’s state estimates (i.e. a model’s parameters) using a known model of the system’s dynamics and statistical noise characteristics. However, it is important to note that although the ‘Kalman solution’ is optimum in a statistical sense, it may yield incorrect state estimates in a absolute deterministic sense.
In contrast, collaborative filtering, typically used in recommendation systems, aggregates data from multiple sensors (or users) to identify patterns and similarities. This approach doesn’t rely on a predefined model of system dynamics but instead leverages historical data to improve accuracy. Collaborative filtering is particularly effective when dealing with large datasets from multiple sensors, making it suitable for applications where the relationships between sensors can be learned and exploited.
Both methods can enhance sensor data reliability, but their effectiveness depends on the context: Kalman filtering for dynamic, real-time systems with welldefined models, and collaborative filtering for complex, multi-sensor environments where data-driven insights are crucial.
In our AIoT work, we implement Collaborative Filtering across multiple M sensors or AIoT edges to achieve consensus on a measured value over a specified interval. Then use a Restricted Boltzmann Machine (RBM) model for collaborative filtering. Additionally, we deploy and run these types of models within a network of IoT edge devices. This approach leverages the distributed computing capabilities of IoT edges to enhance the performance and scalability of our collaborative filtering solution.
The integration of Collaborative Filtering algorithms with CMSIS (Cortex Microcontroller Software Interface Standard) on Arm devices presents a significant advancement in leveraging edge computing for intelligent decision-making. Collaborative Filtering, commonly used in recommendation systems, can be enhanced on Arm Cortex-M processors by utilizing the CMSIS-DSP library. This combination allows for efficient signal processing and data analysis directly on microcontroller-based systems, enabling real-time and power-efficient computations. This approach can be particularly powerful in IoT applications, where Arm devices often operate. By implementing Restricted Boltzmann Machines (RBM) using CMSIS, devices can process and analyze sensor data locally, reducing latency and bandwidth usage. This local computation capability can lead to more responsive and intelligent IoT systems, paving the way for advanced applications in smart environments, healthcare, and personalized user experiences.
Signal Processing on the IoT edge
The objective is to measure the signal \(x_n\)for a duration of \(T\) seconds with a sampling rate \(F_s\). The samples collected during that duration \(T\) are \(r_n=1,2,\ldots N\) samples. These measurements are performed \(M\) times repeatedly. Since there are \(M\) sets of \(x_n\)samples of the signal, the revised objective is to find a representative of these \(M\) sets of samples. Let \(\tilde{x}_n \) be the above-mentioned representative.
Let \(y_m(n) = x(n) + v_m(n) \), where \( v_m(n)\) is the measurement noise during the \(m\)-th measurement.
By performing \(M\) measurements, is it possible to
Improve the Signal to Noise Ratio (SNR)?
Estimate \(x_n\) using Maximum Likelihood and achieve better performance as per the Cramer-Rao bound?
Use a priori information about the source that created \(x_n\)and estimate \(x_n\)using a Bayesian network?
To reduce noise and obtain a more accurate representation of the output signal, multiple measurements of \(y(n)\) are taken over time: \(y_1(n), y_2(n), \ldots, y_M(n) \).
The averaged output signal \(\overline{y(n)} \) is calculated as the mean of these measurements:
Consider a smart thermostat system in a home (part of an AIoT system). The thermostat measures the room temperature \(y(n)\) and adjusts the heating or cooling based on the desired setpoint \(u(n)\).
The following averaging measurement might not yield results that overcome the bounds defined by the Cramer-Rao bound:
\(y_m(n) = x(n) + v_m(n)\)
where \(v_m(n)\) is the measurement noise during the \(m\)-th measurement.
In this context, \(y_m(n) \) represents the noisy measurements of the signal \(x(n)\). Averaging these measurements can reduce the noise variance, but it does not necessarily surpass the theoretical lower bounds on the variance of unbiased estimators, as defined by the Cramer-Rao bound. The Cramer-Rao bound provides a fundamental limit on the precision with which a parameter can be estimated from noisy observations.
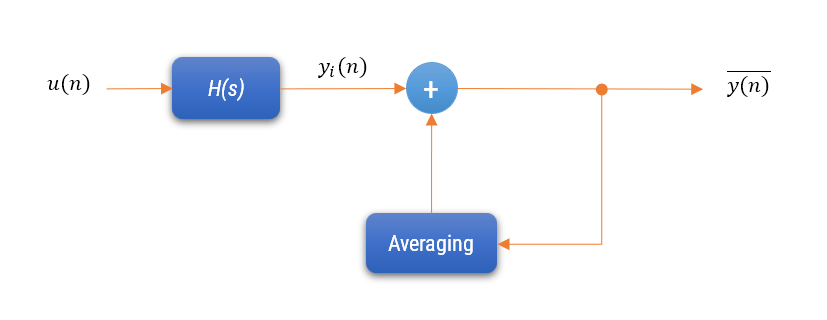
System Description: The thermostat system is represented by \(H(z)\), which controls the heating/cooling based on the input \(u(n)\). The output signal \(y(n)\) represents the measured room temperature.
Multiple Time Measurements: The thermostat takes temperature measurements every minute, producing a set of outputs \(y_1(n), y_2(n), \ldots, y_M(n)\).
Averaging: To get a more accurate representation of the room temperature and to filter out noise (e.g., transient changes due to opening a door), the thermostat averages these measurements: \(\overline{y(n)} = \frac{1}{M} \sum_{i=0}^{M-1} y_i(n)\). By averaging the noisy output values \(y_i(n)\), the thermostat system can make more stable and accurate adjustments, leading to a more comfortable and energy-efficient environment.
Latency: One annoying situation that occurs by the averaging operation, is that it increases the system’s latency, i.e. the smoothed output temperature value lags the observed noisy temperature value taken at time n. This delay is referred to as latency or Group delay in digital filters, and must also be taken into account when designing a closed loop control system. The subject of minimising latency in digital filters can fill a whole book in itself, but suffice to say, IIR digital filters generally have lower latency than FIR filters counterparts. The Moving average filter described herein can be considered as a special case of the FIR filter, as all filter coefficients are equal to one. In order to improve matters, Minimum phase filters (also referred to as zero-latency filters) may be used to overcome the inherent \(N/2\) latency (group delay) in a linear phase FIR filter, by moving any zeros outside of the unit circle to their conjugate reciprocal locations inside the unit circle. The result of this ‘zero flipping operation’ is that the magnitude spectrum will be identical to the original filter, and the phase will be nonlinear, but most importantly the latency will be reduced from \(N/2\) to something much smaller (although non-constant), making it suitable for real-time control applications where IIR filters are typically employed.
AI Model in Signal Processing
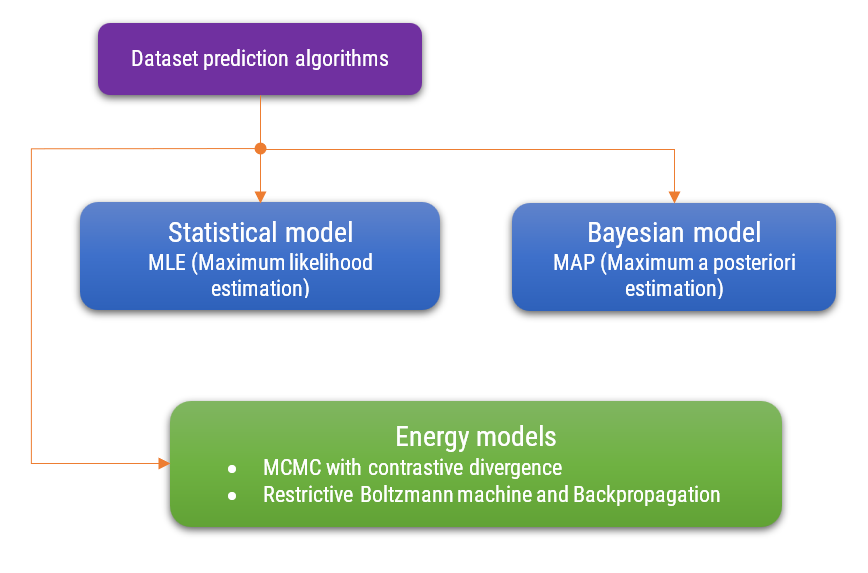
In signal processing, where signals are sensed by sensors, statistical parameterized models, Bayesian networks, and energy models play crucial roles. Statistical parameterized models help in estimating signal parameters efficiently, providing a structured approach to model signal behavior. Bayesian networks offer a probabilistic framework to infer and predict signal characteristics, accommodating uncertainties inherent in sensor data. Energy models, such as those utilizing MCMC with Contrastive Divergence, optimize the representation of signal data by minimizing energy functions, leading to improved signal reconstruction. Similarly, energy models via Restricted Boltzmann Machines and Backpropagation facilitate learning complex signal patterns, enhancing the accuracy of signal interpretation and noise reduction. Together, these models enable robust analysis and processing of signals, crucial for applications like noise reduction, signal enhancement, and feature extraction.
The Cramer-Rao bound (CRB) provides a lower bound on the variance of unbiased estimators, indicating the best possible accuracy one can achieve when estimating parameters from noisy data. This bound applies to traditional estimation methods under certain assumptions, such as unbiasedness and a specific noise model.
MCMC does not directly ‘overcome’ the Cramer-Rao bound, it provides a framework for obtaining parameter estimates that can be more accurate and robust in practice, especially in complex and high-dimensional settings. This improved performance arises from the ability to use prior information, handle complex models, and perform Bayesian inference. Markov Chain Monte Carlo (MCMC) methods, however, are used primarily for sampling from complex probability distributions and performing Bayesian inference. While MCMC methods themselves do not directly ‘overcome’ the CramerRao bound in a traditional sense, they offer advantages in estimation that may be interpreted as achieving better practical performance under certain conditions:
Individual Models
Each model will have ts own bias and variance characteristics. High-capacity models may fit the training data well (low bias) but may perform poorly on new data (high variance). Low-capacity models may underfit the training data (high bias) but have more stable predictions (low variance).
Averaging Models (Ensembles)
By combining the outputs of multiple models, ensemble methods aim to reduce the overall variance. This results in more robust predictions compared to individual models, particularly when the individual models have high variance.
Combining many models seems promising for some applications. When the model capacity is low, it’s difficult to capture the regularities in the data. Conversely, if the model capacity is too large, it may overfit the training data. By using multiple models, such as in AIoT where models can be sensor-centric or device-centric, better results can be achieved compared to using a single huge model.
High-capacity models tend to have low bias but high variance.
Averaging models reduces variance, leading to more stable predictions.
Bias remains unchanged by averaging, so it’s essential to use models with appropriately low bias.
The ensemble approach can outperform individual models by leveraging the strengths of multiple models, especially in scenarios like AIoT, where combining sensor-centric or device-centric models can lead to improved results.
In some cases, an individual predictor may perform better compared to a combined predictor. However, if individual predictors disagree significantly, then the combined predictor can perform well.
AIoT system building blocks
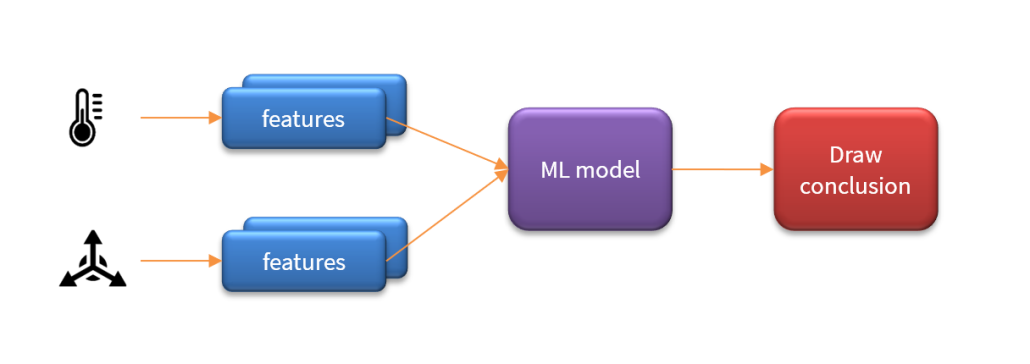
An essential pre-building block in any AIoT system is the feature extraction algorithm. The challenge for any feature extraction algorithm is to extract and enhance any relevant sensor data features in noisy or undesirable circumstances and then pass them onto the ML model in order to provide an accurate classification. The concept is illustrated below:
As seen above, an AIoT system may actually contain multiple feature blocks per sensor and in some cases fuse the features locally before sending them onto the ML model for classification such that the system may then draw a conclusion. The challenge is therefore how to capture sensor data for training and design suitable algorithms to extract features of interest?
The challenge is actually two fold: namely how to capture the datasets for analysis and then which algorithms to use for Feature engineering.
Although a few commercial solutions are available (e.g. Node-RED, Labview, Mathworks Instrumentation toolbox), the latter two are expensive for most developers who just require simple data capture/logging via the UART. One possible solution is Arm’s SDS Framework that provides developers with a set of tools for capturing and playback real-world data using Arm Virtual Hardware. Where, the captured SDS data files can be subsequently converted into a single CSV file for use in 3rd party applications for algorithm development. Unfortunately, the SDS framework is primarily aimed at Arm SoC developers and not particularly suitable for developers working with EVMs/kits. Therefore, most developers use web tools based on AutoML (eg. Qeexo) that will assist with the data capture from hardware (eg. from an ST Nucleo board) and then try an automate the ML modelling process by choosing a set of limited feature extraction algorithms (such as mean, median, standard deviation, kurtosis etc) and then try and produce a suitable classification model. In theory, this sounds great, but there are a number of problems with this approach, as performance is dependent on the quality and relevance of datasets. Our experience has shown that the best performance can be obtained from knowledge of the physical process, and by designing Feature extraction algorithms using scientific principles tailored to the process that you are trying to model.
Example: Feature Engineering for human fall detection
A common requirement of most IoMT biomedical wearable products is detecting Human fall detection with a smartwatch, just using accelerometer data. Traditional fall detection algorithms using MEMS sensors are based on the ‘Falling’ concept, whereby all three axes fall close to zero for a second or so. Although this works well for falling objects, such as a cup or box falling from a table, it is not suitable for humans. The challenge is illustrated below:
As seen, a human’s fall is very different to a box or other object falling.
The challenge is discriminating between normal everyday activities and falls. By analysing datasets of net acceleration data of typical everyday activities, such as someone walking, using their smartphone, brushing their teeth or doing some morning exercises, and fall data it is not always easy to discriminate between the two using ’standard’ statistical features.
Therefore, we need to apply some physics to the process that we’re trying to model in order to derive specific features from the sensor data, so that we can make a classification – i.e. is it a fall, or not.
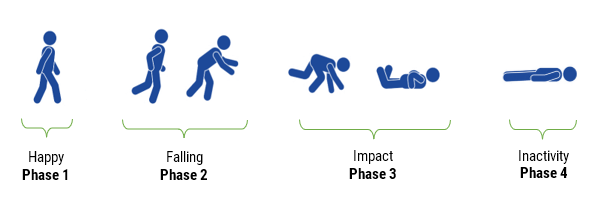
Analysing the diagram we see that there are actually 4 phases from where the person is standing through to the point of the person lying on the ground. So the big question is how do we go about modelling these phases just using accelerometer data? This is best analysed by breaking the fall up into phases:
Happy: where the subject is upright and going about their daily business.
Falling: Depending on the subject, this period can be very short (around 100ms) and manifests itself very differently to an object falling directly down (i.e. freefall). The net acceleration will usually manifest itself as a negative gradient starting from about 1g tending towards zero, as the body’s centre of gravity changes. This usually lasts for about 60-100ms.
Impact: this is the primary event to detect, as any impact from a standing posture with a hard surface will produce a large shock pulse that is several orders of magnitude >1g over a short period.
Inactivity: this usually follows impact with the ground, whereby the subject is lying flat and is motionless for several seconds. In the case of a collision with an object (e.g. a piece of furniture or a door) or as a result of a severe medical condition, such as a stroke or heart attack, the subject may become unconscious. In this case, the system should be able to discriminate between inactivity from normal movements, such as hand or slight limb movement and light movement (caused by breathing) and decide whether to alert medical services. In the case that no movement is detected, i.e. the subject may have died as a result of the fall, there is no need to provide swift medical assistance.
Armed with this knowledge we can now use Feature engineering to design our features. This forms the essence of building features based on understanding of the physical process.
What tools and processor technology are available?
Although a few processor technologies exist for microcontrollers (e.g. RISC-V, Xtensa, MIPS), over 90% of the microcontrollers used in the smart product market are powered by so-called Arm Cortex-M processors. These are split up into various market segments, depending on energy requirements and algorithmic performance.
The low-end cores, such as the M0, M0+ and M3 are good for simpler algorithms, such as sensor cleaning filters, simple analytics as they have limited memory and no hardware FP support. To give you an idea of performance, for those of you who own a Fitbit, this is based on the M3 processor.
However, the biggest plus (especially for the M0 family), is that they can have very low power footprint making them an ideal choice for coin cell battery powered wearable applications, as devices can be made to run for months and even in some cases up to a year.
For developers looking for decent computational performance, the M4F is an excellent choice as it has hardware FP support, which is ideal for rapid application development of algorithms. In fact, the Arm Cortex-M4 is a very popular choice with several silicon vendors (including ST, TI, NXP, ADI, Nordic, Microchip, Renesas), as it offers DSP (digital signal processing) functionality traditionally found in more expensive devices and is low-power.
If you need more your application needs more computational performance, then the M7 is an excellent choice, where some devices even offer H/W double precision floating point support, which is ideal for audio enhancement and biomedical algorithms.
For those of you looking for hardware security, then the M33 is a good choice, as it implements Arm TrustZone security architecture, as well as having the computational performance of the M4.
State-of-the art AIoT microcontrollers
Released in 2020, the Arm Cortex-M55 processor and its bigger brother the Cortex-M85 are targeted for AIoT applications on microcontrollers. These processors use Arm’s powerful Armv8.1-M architecture that implement their M-Profile Vector Extension (MVE) technology (nicknamed Helium) allowing for 128bit vector mathematical operations (such as dot product operations) needed for ML and some DSP algorithms.
In November 2023, Arm announced the release of the Cortex-M52 processor for AIoT applications. This processor looks to replace the older M33 processor, as it combines Helium technology with Arm TrustZone technology. However, as only a few IC vendors (Alif, Ambiq, Samsung, Renesas, HiMax, Bestechnic, Qualcomm) have currently released or are planning to release any devices, Helium processors remain a gem for the future.
Toolchains
Arm provides developers with extensive easy-to-use tooling and tried and tested software libraries. The Arm’s CMSIS-DSP and CMSIS-NN frameworks for algorithm development and machine learning (ML) are two very popular examples that are open source and are used internationally by tens of thousands of developers.
The Arm-CMSIS framework solutions are further strengthened by Arm partners ASN and Qeexo who provide developers with easy-to-use real-time filtering, feature extraction (ASN Filter Designer) and ML tooling (Qeexo AutoML) and reference designs, expediting the development of IoT applications, including industrial, audio and biomedical. These solutions have been optimised for Arm processors with the help of Arm’s architecture experts and insider knowledge of compiler workings.
Deployment of Deep Learning Networks to the IoT Edge
Deploying a trained model onto an Edge device requires meticulous attention and effort. Fortunately, there are many tools available to help developers achieve this, such as Qeexo AutoML and the DLtrain toolset. The latter offers robust support for developers working with Arm processor-based boards with Android platforms. DLtrain utilizes the Android NDK (native development kit) to deploy neural networks (NN) or convolutional neural networks (CNN) in the Linux kernel of the Android platform. The deployed components include JNI options to support applications developed in Java, bridging the gap between low-level implementation and high-level application development. Find out more here.
Deploying deep learning (DL) networks on Arm cores of Android platforms involves integrating these networks into the Linux kernel via the Android NDK. While application development is primarily done in Java, DL networks receive input from the Android layer (SDK) and efficiently perform inference. The results are then passed back to the Java side via the Java Native Interface (JNI). The following list describes the layers involved in performing inference on an Android device:
Top Layer: User Interface
Second Layer: Java
Third Layer: Android SDK
Fourth Layer: Arm
Bottom Layer: GPU
This hierarchical structure ensures that the user interface seamlessly interacts with underlying DL networks, optimizing performance and maintaining an efficient workflow from input to inference to output.
Key takeways
AI is an umbrella term focused on creating intelligent systems, whereas MLis a subset of AI that involves creating models to learn from data and make decisions. ML is crucial for IoT because it enables efficient data analysis, predictive maintenance, smart automation, anomaly detection, and personalized user experiences, all of which are essential for maximizing the value and effectiveness of IoT deployments.
Arm and its rich ecosystem of partners provide IoT developers with extensive easy-to-use tooling and tried and tested software libraries for designing an implementing IoT algorithms for their smart products. Arm Cortex-MxF processors expedite RAD by virtue of their ease of use and hardware floating-point support, and modern semiconductor technology ensures low-power profiles making the technology an excellent fit for IoT/AIoT mobile/wearables applications.
Sanjeev is a RTEI (Real-Time Edge Intelligence) visionary and expert in signals and systems with a track record of successfully developing over 25 commercial products. He is a Distinguished Arm Ambassador and advises top international blue chip companies on their AIoT/RTEI solutions and strategies for I4.0, telemedicine, smart healthcare, smart grids and smart buildings.
Jayakumar is an Arm ambassador and seasoned expert in semiconductor technology and AIoT. He advices companies such as Mistral Solutions, SunPlus Software, and Apollo Tyres at the strategic level on their AIoT solutions. He successfully founded Epigon Media Technologies, which focuses on Research and Development for the global market, and is also the co-author of the book "Deep Learning Networks: Design, Development, and Deployment."
https://www.advsolned.com/wp-content/uploads/2024/06/aiot_human-scaled.jpg13622560Dr. Sanjeev Sarpalhttps://www.advsolned.com/wp-content/uploads/2018/02/ASN_logo.jpgDr. Sanjeev Sarpal2024-06-25 15:47:532024-07-04 09:25:06AI, ML and AIoT: a unified view of concepts, toolchains and Arm processor technology for IoT developers
Unexpected equipment failures can be expensive and potentially catastrophic, resulting in unplanned production downtime, costly replacement of parts and safety and environmental concerns. With many factories and process control plants facing an ever-increasing shortage of experienced personnel, many are now looking for AI based systems to replace the ‘experienced old guy’ who knows everything about the machine and reduce their Total Cost of Ownership (TOC).
The challenge is however, how do you build and train an AI CbM system to replace an expert ?
What is CbM?
As part of the I4.0 revolution, Condition based monitoring (CbM) of machines has received a great amount of attention, as factories look to maximise their production efficiency and reduce their TOC, while at the same time retaining the invaluable skills of experienced foremen and production workers. As such, CbM is a process for monitoring equipment during operation to identify any deterioration, enabling maintenance to be planned and operational costs reduced.
CbM 5G edge computing
Many are factory owners are suspicious of cloud-based enterprise solutions offered by Microsoft, Amazon and Google as data leaves the site and any latency issues could affect production output. Recently 5G edge computing has received much attention, whereby all time-critical operations are undertaken at the edge (i.e. near to the asset in the factory) via smart sensors.
Arm’s rich set of Cortex processors offer a combination of high performance, ML/DSP computation support and low power. This is further strengthened by Arm’s new Helium Cortex-M55 and Cortex-M85 AI based processors that have been specially designed for edge-based AI applications – the latter offers an impressive 3DMIPS/MHz making it a good fit for ML and DSP algorithms. These processors and supporting libraries now allow developers to develop high-performance CbM smart sensors to perform their computationally intensive tasks at the edge and communicate the results via a 5G network to a smartphone or database. This provides higher reliability and scalability than expensive cloud-based solutions reliant on big data.
It would seem that big data has had its day!
Vibration sensor technology
Contactless MEMS (microelectromechanical systems) accelerometers sensors are an excellent alternative to the well-established, but bulky and expensive (25-500+ EUR) Piezo sensors for obtaining vibration information. MEMS sensors are relatively low cost (10-30 EUR) and can offer a response down to DC (zero Hertz), which is useful for the detection of imbalance at very low rotational speeds. MEMS accelerometers also have a self-test feature whereby the sensor can be verified to be 100% functional. They produce acceleration data that can be analysed by various vibration monitoring algorithms.
Spectral vibration monitoring via the FFT (Fast Fourier Transform) is regarded as an industry standard for machine vibration analysis. If a mechanical problem exists, the FFT spectra (multiple spectrums) will provide information to help determine the source and cause of the problem. Coupled with the right AI algorithms, the features from the FFT analysis can be used to identify the root cause of the failure, such as motor imbalance, misalignment, and looseness. These properties and challenges faced by the FFT will be discussed further later on in the article.
There are several steps to follow as guidelines to help achieve a successful vibration monitoring programme. The following is a general list of these steps:
Collect useful information: Look, listen and feel the machinery to check for resonance. Identify what measurements are needed (point and point type). Conduct additional testing if further data are required.
Analyse spectral data: Evaluate the overall values and specific frequencies corresponding to machinery anomalies. Compare overall values in different directions and current measurements with historical data.
Multi-parameter monitoring: Use additional techniques to conclude the fault type. (Analysis tools such as phase measurements, current analysis, acceleration enveloping, oil analysis and thermography can also be used.)
Perform Root Cause Analysis (RCA): In order to identify the real causes of the problem and to prevent it from occurring again.
Reporting and planning actions: Use a Computer Maintenance Management System (CMMS) to rectify the problem and take action to achieve a plan.
As aforementioned, a popular device used to obtain acceleration data is a so-called ‘accelerometer’. These devices are semiconductor-based MEMS (microelectromechanical systems) and provide 3D (i.e. tri-axial) acceleration time domain data to a supporting microcontroller.
Before FFT analysis, the accelerometer data is usually passed through integration signal processing blocks, in order to convert the time domain acceleration data into velocity and displacement data. These blocks are comprised of a highpass filter and cumulative sum (integration). The highpass filter is essential for removing the effects of DC and noise, which would cause an offset in the output (i.e. the result of the integration). Depending on the severity of the noise/DC the output may even saturate, making it unusable for analysis. The design of a suitable highpass filter is an extremely challenging task and is the primary reason why many vibration analysis systems struggle to measure vibrations <10Hz (600 RPM).
Collect useful information
When conducting a vibration program, certain preliminary information is needed in order to conduct an analysis. The identification of components, running speed, operating environment and types of measurements should be determined initially to assess the overall system.
Identify components of the machine that could cause vibration
Before a spectrum can be analysed, the components that cause vibration within the machine must be identified. For example, you should be familiar with these key components:
If the machine is connected to a fan or pump, it is important to know the number of fan blades or impellers.
If bearings are present, know the bearing identification number or its designation.
If the machine contains, or is coupled, to a gearbox, know the number of teeth and shaft speeds.
If the machine is driven with belts, know the belt lengths.
The above information helps assess spectral components and helps identify the vibration source. Determining the running speed is the initial task. There are several methods to help identify this parameter.
Identifying the running speed
Knowing the machine’s running speed is critical when analysing an FFT spectrum. Running speed is related to most components within the machine and therefore, aids in assessing overall machine health. There are several ways to determine running speed:
Read the speed from instrumentation at the machine or from instrumentation in the control room monitoring the machine.
Look for peaks in the spectrum at 1,800 or 3,600 RPM (60Hz countries), 1,500 and 3,000 RPM (50Hz countries) if the machine is an induction electric motor, as electric motors usually run at these speeds. If the machine is variable speed, look for peaks in the spectrum that are close to the running speed of the machine during the time at which the data is captured.
An FFT’s running speed peak is typically the first significant peak in the spectrum when reading the spectrum from left to right. Search for this peak and check for peaks at two times, three times, four times, etc. (at the harmonic frequencies).
Challenges with the FFT algorithm
FFT spectra allow us to analyse vibration amplitudes at various component frequencies on the FFT spectrum. In this way, we can identify and track vibration occurring at specific frequencies. Since we know that particular machinery problems generate vibration at specific frequencies, we can use this information to diagnose the cause of excessive vibration.
Challenges with spectral analysis
The sampling rate of the accelerometer drifts with temperature: This results in a mismatch between the FFT analysis sampling frequency and the real situation. As such, the amplitude and frequency estimates of the vibration will be incorrect.
Frequency resolution: the frequency of the vibration peak may have a fractional value. If the resolution of the Fourier algorithm is not fine enough, it will ‘smear’ the result, resulting in a lower amplitude estimate.
Running speed: this is typically known apriori, but will have a degree of error associated with it and will change with temperature. For example, 3000 rpm ±1% is 50Hz ±0.5Hz at the fundamental running frequency. In order to track higher harmonics (i.e. multiples of the running speed) the FFT must have sufficient frequency resolution to accurately estimate the amplitude at the right frequency.
Traditional FFT based analysis uses a very high number of computational points in order to achieve a 1Hz resolution. Although this is OK, it still does not overcome the fractional frequency components and requires considerable computational effort.
Some designs use a phaselocked loop, that tracks the running frequency and sets the FFT analysis sampling frequency to a multiple (e.g. 20x) of the running speed. Although this is a very good workaround, it requires specialised hardware (such as an expensive ASIC) and is inflexible for changes in running speed.
ML feature extraction, DSP algorithms and models
In order to build an ML (machine learning) model for an AI CbM application, several challenges need to be overcome.
Definition of classes: In order to make a classification, ML classes must be defined. In the simplest sense, this can be Fault or Normal behaviour, but what about other cases?
ML Features: what data features will be used for the ML model? Running speed, harmonics, RMS amplitude? What physical and mathematical principles should I use to build these algorithms?
Obtaining ML training data: How will you obtain suitable datasets for ML training? In many cases this is not easy to obtain, as many foremen will not allow any disruption to their time-critical production lines.
Preparing datasets: After answering the aforementioned questions, the next challenge will be to capture and prepare the datasets for the ML classification. This is traditionally where a good 90% of a data scientist’s time will be spent. Therefore, it is prudent to invest in high fidelity feature extraction edge algorithms in order to expedite this step. This will also have the advantage of increasing the reproducibility and consistency of the results, which is where many AI based systems perform poorly.
ASN’s IP blocks and applications
ASN’s vibration IP blocks combine the Fourier transform’s time-frequency integration property, data filtering and a specialised high frequency resolution tracking algorithm to implement the ARAHTA (adaptive running speed and harmonics tracking) algorithm. ARAHTA tracks the vibration sensor’s ODR (output data rate) and calculates the motor/pumps running speed using the sensor’s accelerometer sensor data in real-time. ARAHTA’s high resolution and adaptive tracking mechanism results in a typical running speed accuracy of ±1 RPM across the temperature range and sub-mm displacement accuracy using noisy accelerometer data.
ARAHTA’s high accuracy and flexibility ensures that the resulting ML features are high quality and very consistent in the presence of temperature change and load shifts. This has a significant advantage for CbM applications, whereby fingerprinting a spectral profile can be used to assess the degradation of assets of interest. ARAHTA’s high-resolution spectrum forms the basis of providing an AI algorithm with high accuracy feature-rich information, suitable for classification.
Algorithmic performance
A comparison of the FFT vs the ASN ARAHTA IP blocks is shown below. Setting up a test accelerometer signal comprised of an 8.2Hz sinusoid with amplitude 1gand a few harmonic frequencies at various amplitudes, we can objectively compare the methods.
Analysing Figure 1, notice that the plot shows a comparison of the acceleration spectrum (i.e. the FFT of the acceleration data, shown in red) and the displacement spectrum, shown in blue. Analysing the first peak, notice that as the FFT’s resolution is insufficient, as the algorithm has identified the peak at 8.75Hz, rather than at 8.2Hz. This has a consequence for the amplitude estimation, as the acceleration spectrum amplitude is around 0.34g, rather than the expected 1g. As such, the algorithm incorrectly estimates the displacement at 8.2Hz to be 1mm, rather than 3.69mm.
The true value can be seen in Figure 2, where ARAHTA correctly finds the first resonant peak at 8.2Hz and estimates the correct amplitude of 3.69mm.
Figure 1 – Displacement estimate via FFT (frequency resolution: 813.5mHz): wrong frequency and amplitude estimation
Figure 2 – Displacement estimate via ARAHTA (frequency resolution: 10mHz): correct amplitude and frequency estimation.
Get in touch and reduce your asset’s TCO
ASN contactless measurement sensor technology and smart algorithms are an ideal solution for AI based CbM applications. Please contact our CbM expert team to see how we can help you create an effective maintenance programme and reduce your asset’s Total Cost of Ownership.
Sanjeev is a RTEI (Real-Time Edge Intelligence) visionary and expert in signals and systems with a track record of successfully developing over 25 commercial products. He is a Distinguished Arm Ambassador and advises top international blue chip companies on their AIoT/RTEI solutions and strategies for I4.0, telemedicine, smart healthcare, smart grids and smart buildings.
https://www.advsolned.com/wp-content/uploads/2019/12/induction-motor-1500-580-4_compres2.jpg5801500Dr. Sanjeev Sarpalhttps://www.advsolned.com/wp-content/uploads/2018/02/ASN_logo.jpgDr. Sanjeev Sarpal2022-03-02 17:47:312023-05-12 09:23:54Deploying AI based CbM applications: challenges and algorithmic solutions
ASN Filter Designer’s new ANSI C SDK framework, provides developers with a comprehensive automatic C code generator for microcontrollers and embedded platforms. This allows developers to directly deploy their AIoT filtering application from within the tool to any STM32, Arduino, ESP32, PIC32, Beagle Bone and other Arm, RISC-V, MIPS microcontrollers for direct use.
Arm’s CMSIS-DSP library vs. ASN’s C SDK Framework
Thanks to our close collaboration with Arm’s architecture team, our new ultra-compact, highly optimised ANSI C based framework provides outstanding performance compared to other commercial DSP libraries, including Arm’s optimised CMSIS-DSP library.
Benchmarks for STM32: M3, M4F and M7F microcontrollers running an 8th order IIR biquad lowpass filter for 1024 samples
As seen, using o1 complier optimisation, our framework is able to surpass Arm’s CMSIS-DSP library’s performance on an M4F and M7F. Although notice that performance of both libraries is worse on the Cortex-M3, as it doesn’t have an FPU. Despite the difference, both libraries perform equally well, but the ASN DSP library has the added advantage of extra functionality and being platform agnostic, making it ideal for variety of biomedical (ECG, EMG, PPG), audio (sound effects, equalisers) , IoT (temperature, gas, pressure) and I4.0 (flow measurement, vibration analysis, CbM) applications.
AIoT applications designed on the newer Cortex-M33F and Cortex-M55F cores can also take advantage of extra filtering blocks, double precision arithmetic support, providing a simple way of implementing high performance AI on the Edge applications within hours.
Advantages for developers
A developer can now develop, test and deploy a complete DSP filtering application within the ASN Filter Designer within a few hours. This is very different from a traditional R&D approach that assigns a team of developers for several days in order to achieve the same level of accuracy required for the application.
Open source and agnostic code base: In order to allow developers to get the maximum performance for their applications, the ASN-DSP SDK is provided as open source and is written in ANSI C. This means that any embedded processor and any level of compiler optimisation can be used.
Memory size required for the ASN-DSP SDK is relativity lower than other standard DSP libraries, which makes the ASN-DSP SDK extremely suitable for microcontrollers that have memory constrains.
Using the ASN Filter Designer’s signal analyser tool, developers now can test the performance, accuracy and assess the frequency response of their designed filter and get optimised C code which they can directly use in their application.
The SDK also supports some extra filtering functions, such as: a median filter, a moving average filter, all-pass, single section IIR filters, a TKEO biomedical filter, and various non-linear functions, including RMS, Abs, Log and Sqrt. These functions form the filter cascade within the tool, and can be used to build signal processing applications, such as EMG and ECG biomedical applications.
The ASN-DSP SDK supports both single and double precision floating point arithmetic, providing excellent numerical accuracy and wide dynamic range. The library is unique in the sense that it supports double precision arithmetic, which although is not the most optimal for microcontrollers, allows for the implementation of high-fidelity filtering applications.
The ANSI C SDK framework is further extended by our new C# .NET framework, allowing .NET developers to build high performance desktop applications with signal processing capabilities.
Find out more and try it yourself
Benchmarks on a variety of 32-bit embedded platforms, including a biomedical EMG filtering example, are covered in the following application note.
The both framework SDKs are available in ASNFD v5.0, which may be downloaded here.
AIoT has many benefits. Those benefits can be summarized as: saving, controlling, optimizing and innovation. How does AIOT reduce costs and provide more efficiency?
How AIoT can help to save:
Preventive maintenance
Efficient use of time, equipment and money
Lesser costs of energy
Don´t throw away infrastructure which is working fine
Preventive maintenance
Purchasing new machinery involves high costs. The assets of public infrastructure exist of expensive equipment. So, there are high costs of replacing equipment which is failing. To reduce these costs, Preventive maintenance comes in. With Preventive maintenance, you can repair or replace parts from which you know that they will not be working properly in a short time. Or on the moment they are not working properly anymore. With this maintenance program, you can act because an (expected) little failure has caused damage.
And, in many cases such as public infrastructure, a not working device isn’t just a not working device! A failure of a sluice or railroad switch causes disruption for the infrastructure as a whole: Ships and trains can’t deliver their goods anymore on time. Customers are standing literary in the cold due to not working train infrastructure. With preventive maintenance you can spare them (or yourself) high costs and much annoyance.
Efficient use of time, equipment and money
Use your time, equipment or money? As efficient as possible. In a time of growing economies, employees are scarce and hard to find. So you want to make use of your employee’s time as efficient and effective as possible. This means that employees have to to be able give attention to things… really needed. IoT makes this possible. Some examples:
For offices: cleaners have to clean only the places of the office which have actually used instead of cleaning the whole building. Non-used offices can even be shut down.
Logistics: more efficienct planning of cranes, further transport
Already mentioned: the benefit of preventive maintenance
Lesser costs of energy
Another savings IoT makes possible is saving of energy.
And of course, this benefits the user but also the planet as a whole! And that makes your customers and employees even more satisfied. Which makes that they will stay customer or employer longer… Besides, if you rent offices, they will be longer and easier hired.
Don’t throw infrastructure which is working fine
In most buildings and logistics, the infrastructure has been built years ago with huge efforts and costs. The infrastructure is mission critical, so owners often still accept that their infrastructure isn’t the most efficient, as long as it works. Now sensors come in: they bring an extra layer upon the already existing devices, be it such different devices as hvac in office buildings or cranes in ports.
https://www.advsolned.com/wp-content/uploads/2021/06/smart-city-icons.jpg6931039ASN consultancy teamhttps://www.advsolned.com/wp-content/uploads/2018/02/ASN_logo.jpgASN consultancy team2021-06-30 10:15:002021-06-30 13:17:55The Benefits of AIOT: “Lower Costs or More Efficiency”