Drones and DC motor control – How the ASN Filter Designer can save you a lot of time and effort
Drones are one of the golden nuggets in IoT. No wonder, they can play a pivotal role in congested cities and far away areas for delivery. Further, they can be a great help to give an overview of a large area or places which are difficult or dangerous to reach. However, most of the technology is still in its experimental stage.
Because drones have a lot of sensors, Advanced Solutions Nederland did some research on how drone producing companies have solved questions regarding their sensor technology, especially regarding DC motor control.
Until now: solutions developed with great difficulty
We found out that most producers spend weeks or even months on finding solutions for their sensor technology challenges. With the ASN Filter Designer, he/she could have come to a solution within days or maybe even hours. Besides, we expect that the measurement would be better too.
The biggest time coster is that until now algorithms were developed by handwork, i.e. they were developed in a lab environment and then tested in real-life. With the result of the test, the algorithm would be tweaked again until the desired results were reached. However, yet another challenge stems from the fact that a lab environment is where testing conditions are stable, so it’s very hard to make models work in real life. These steps result in rounds and rounds of ‘lab development’ and ‘real life testing’ in order to make any progress -which isn’t ideal!
How the ASN Filter Designer can help save a lot of time and effort
The ASN Filter Designer can help a lot of time in the design and testing of algorithms in the following ways:
- Design, analyse and implement filters for drone sensor applications with real-time feedback and our powerful signal analyser.
- Design filters for speed and positioning control for sensorless BLDC (brushless DC) motor applications.
- Speed up deployment to Arm Cortex-M embedded processors.
Real-time feedback and powerful signal analyser
One of the key benefits of the ASN Filter Designer and signal analyser is that it gives real-time feedback. Once an algorithm is developed, it can easily be tested on real-life data. To analyse the real-life data, the ASN Filter Designer has a powerful signal analyser in place.
Design and analyse filters the easy way
You can easily design, analyse and implement filters for a variety of drone sensor applications, including: loadcells, strain gauges, torque, pressure, temperature, vibration, and ultrasonic sensors and assess their dynamic performance in real-time for a variety of input conditions. With the ASN Filter Designer, you don’t have do to any coding yourself or break your head with specifications: you just have to draw the filter magnitude specification and the tool will calculate the coefficients itself.
Speed up deployment
Perform detailed time/frequency analysis on captured test datasets and fine-tune your design. Our Arm CMSIS-DSP and C/C++ code generators and software frameworks speed up deployment to a DSP, FPGA or micro-controller.
An example: designing BLDC motor control algorithms
BLDC (brushless DC) BLDC motors have found use in a variety of application areas, including: robotics, drones and cars. They have significant advantages over brushed DC motors and induction motors, such as: better speed-torque characteristics, high reliability, longer operating life, noiseless operation, and reduction of electromagnetic interference (EMI).
One advantage of BLDC motor control compared to standard DC motors is that the motor’s speed can be controlled very accurately using six-step commutation, making it a good choice for precision motion applications, such as robotics and drones.
Sensorless back-EMF and digital filtering
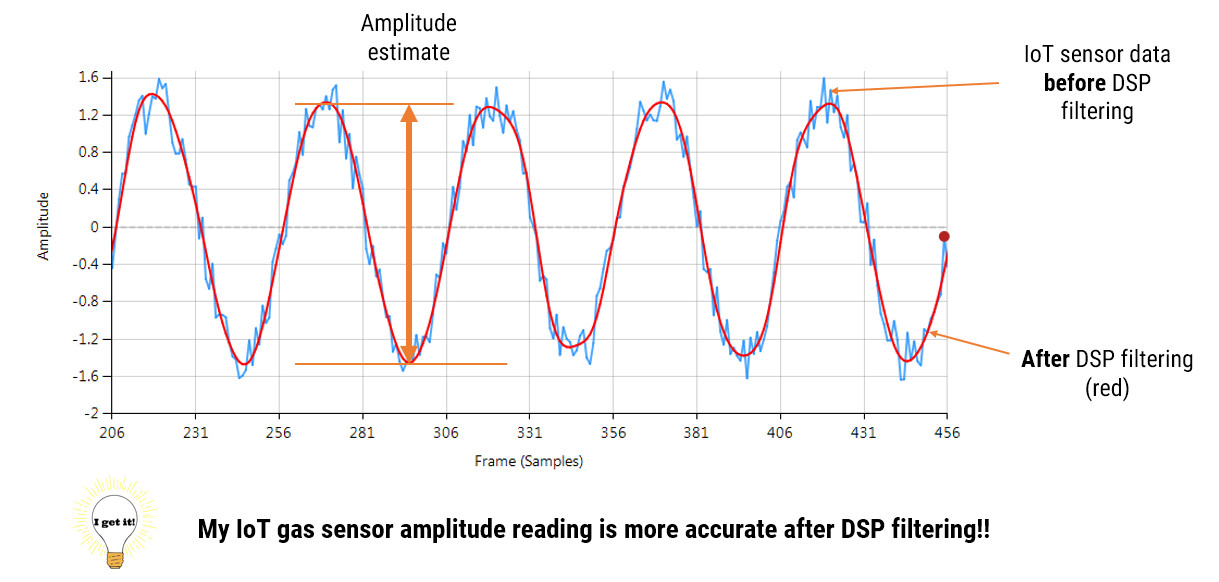
For most applications, monitoring of the back-EMF (back-electromotive force) signal of the unexcited phase winding is easier said than done, since it has significant noise distortion from PWM (pulse width modulation) commutation from the other energised windings. The coupling between the motor parameters, especially inductances, can induce ripple in the back-EMF signal that is synchronous with the PWM commutation. As a consequence, this induced ripple on the back EMF signal leads to faulty commutation. Thus, the measurement challenge is how to accurately measure the zero-crossings of the back-EMF signal in the presence of PWM signals?
A standard solution is to use digital filtering, i.e. IIR, FIR or even a median (majority) filter. However, the challenge for most designers is how to find the best filter type and optimal filter specification for the motor under consideration.
The solution
The ASN Filter Designer allows engineers to work on speed and position sensorless BLDC motor control applications based on back-EMF filtering to easily experiment and see the filtering results on captured test datasets in real-time for various IIR, FIR and median (majority filtering) digital filtering schemes. The tool’s signal analyser implements a robust zero-crossings detector, allowing engineers to evaluate and fine-tune a complete sensorless BLDC control algorithm quickly and simply.
So, if you have a measurement problem, ask yourself:
Can I save time and money, and reduce the headache of design and implementation with an investment in new tooling?
Our licensing solutions start from just 125 EUR for a 3-month licence.
Find out what we can do for you, and learn more by visiting the ASN Filter Designer’s product homepage.